
To understand technical debt, we have to turn the clock back and consider how most commercial applications originating in the 1980’s and early 1990’s were developed. This was before DB2 for i (as it is known today) or relational database engines reached maturity and before the introduction of the ILE programming model.
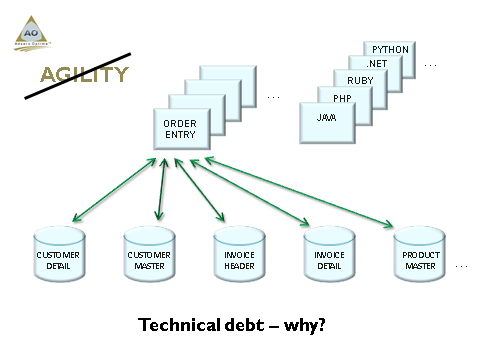
Although we had an integrated relational database engine on the System/38 since announcement (1978/9), due to the immaturity of relational databases, it was initially effectively a collection of “flat files”. All entity relationships and data validation rules (valid values, casting, etc.) was enforced within our HLL code.
Should you consider that the average LOB (Line of Business) application from this era consisted out of approximately 1 500 – 2 500 individual program objects, and then consider that EVERY single program that manipulates ANY of the entities (aka physical files or tables), MUST (theoretically) have EXACTLY the same validations rules and relationships enforced, you can begin to understand the significance of ANY maintenance request that involved a change to a field (column) or file (table). To put this in context – MOST maintenance requests will USUALLY entail such changes…
All of us need to acknowledge that we essentially coded relational database logic, using our HLL’s of the time, due to the relative immaturity of relational database engines at that time. The 1980’s and 1990’s was a time of dramatic strategic advances in software engineering in particular.
With the introduction of the ILE programming (OS/400 V2R3) model, shortly followed by the new ILE RPG compiler on the AS/400 in 1993/4 time-frame, all our heritage applications essentially was “broken” from an architectural perspective. One of the fundamental considerations of the ILE programming model, was to facilitate “code re-use”, having a single instance of a piece of logic, and re-using this logic, when required. It is also allows for mixing languages dynamically and sharing job control and program storage interchangeably…
DB2 also advanced dramatically in this same time-frame. This was the “golden days” of the AS/400 (our proud heritage), with rapid development and achievements (CISC to RISC, etc. etc.), especially in terms of sales and excitement around the platform. The remarkable fact (which these days “haunts” us to a certain degree) was how well IBM protected and insulated us from all the changes… our heritage applications happily kept on running, producing the goods, creating the FALSE sense of security that all was well…
Also during this time, our applications moved from essentially online capturing of information with batch processing, to integrated OLTP. It was remarkable how well our applications (and developers) adapted. IBM Rochester achieved some remarkable feats, allowing the developers and users of the AS/400 and successor platforms to achieve something other manufacturers still dream off… However, our applications was ANTIQUATED in their construction methods and was a ticking time bomb…
Add to this the industry move to client/server and then the exposure of our applications to the Internet and mobile devices, using fat or thin clients (or mixture), and we had simply too many demands on our stretched development resources. Many changes became very difficult, especially if it involved field (column) and/or file (table) changes, as we had to find every single instance where that entity (file) or data element (field) was manipulated. If we missed ANY, data corruption potentially occurred…
Adding to this highly toxic recipe, many of the early adopters of JAVA and other development environments and languages, accessed and manipulated our DB2 files (tables) directly, DUPLICATING the same validation and relationship code – a recipe for disaster and duplicate/triplicate/quadruple/”to infinite and beyond” maintenance burden. Even worse, the opportunity for data corruption was increased by orders of magnitude… And attempting to isolate the "rogue" code inserting invalid data, next to impossible to find...
If it wasn’t for the protection and reliability of this amazing platform and architecture, most companies and developers would have ended up involved in untold horrors…
What should have happened in the mid 1990’s, was the gradual modernization of our applications, leveraging the ILE programming model and the advances in the database engine, implementing “data centricity”. Contrary to popular belief, we actually did have implementations of “data centricity” from the mid-1980’s, with application development tools such as Genesis V and Synon 2E. Synon 2E (now CA2E) and Simon Williams specifically was decades ahead of its time, from being completely data centric in it’s design and coding paradigm.
However, the squeeze was already on in IT spend, with the C-suite expecting more for less… and our applications was happily producing the goods, so why worry???
As a result, very little REAL modernization happened, at best a little lipstick (on a VERY ugly pig by now), if the users complained too much about our “green screens”…
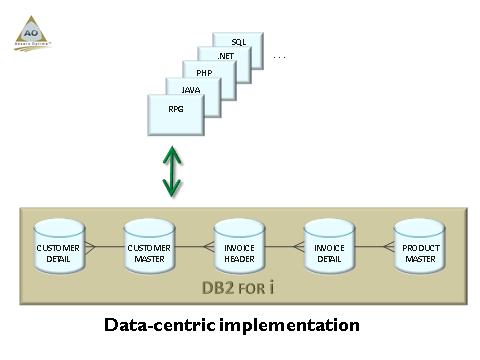
As indicated in my previous picture, we should have started to adopt and implement “data centricity” in the mid 1990’s, allowing DB2 to look after ALL data validations and entity relationships, making the database “self aware” and placing DB2 (and NOT our HLL code) in control of integrity.
Please note that “data centricity” does NOT mean SQL. And SQL does NOT mean “data centricity”. It means that the database is in CONTROL of enforcing all entity relationships and data validations, preventing ANY client (RPG, JAVA, .NET, SQL, etc.) from injecting ANY inaccurate or incomplete data into your database. Data centricity CAN be achieved with your existing applications, improving your data quality and integrity by orders of magnitude.
ALSO, please acknowledge that we now have SIX (6) “logical” database constructs at our disposal – 3 defined in DDS and three in DDL (DDS View, DDS Join, DDS Multi-Format, DDL EV Index, DDL BR Index, DDL View). The DDL constructs DO NOT replace the DDS constructs. ALL of these constructs are different, each with its unique characteristics. Get to know these INTIMATELY, as the combination of them is an EXCEPTIONALLY powerful tool in your arsenal.
Additionally, it will facilitate an exceptionally AGILE development environment, allowing you to RAPIDLY respond to changes in the business environment. An added benefit is that you can use tried, tested and stable code for enforcing single instances of these rules INSIDE DB2, no longer in our HLL code…
And no matter which “client” (RPG, COBOL, SQL, C, C++, JAVA, PHP, Python, choose your language) access our “self-aware” database and receive the same record or result set. It is ALL about single instance, re-usable code. A single place where maintenance is performed, as opposed to n-times…
It also implies that our database will GRADUALLY become a true relational database, with proper normalization enforced, long file and field names exposed, etc…
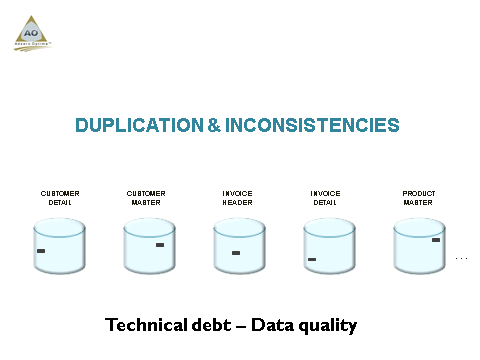
An issue few people acknowledge is what has happened to our data quality and integrity, due to DECADES of neglect. Again, due to old programming constructs and development methodologies which originated in the 1980’s, it is not unusual to see MULTIPLE versions of the truth of the same data element in our business processes, depending where we find ourselves in the business processes. As a result, executives may often look at the incorrect data element when making decisions…
Again this amazing platform SHIELDED us from potential disaster. What should have happened when DB2 on i became the amazing engine it is today, was the implementation of proper data management and data engineering principles. We should have started managing our metadata (the data describing our data) and the quality of our data a LOT more stringently, as is expected on ANY of the competing platforms.
To allow you to grasp the significance of what we are trying to highlight: it is not unusual for us to see more than 50 000 discrete data elements in “use” in the average IBM i LOB application, whilst experience suggests that 1,500 discrete metadata elements would be the number of metadata elements that one could expect to find in the average LOB application.
Now… consider for a moment that your developers are using HLL code to keep the contents of these metadata elements in sync, and you will acknowledge the IMMENSE waste of time that is taking place. Not only that, but consider for a moment the impact of not keeping these elements in sync, or even worse, inconsistencies… Imagine what the quality of decision making is… then, extrapolate this with the advent of predictive analytics and cognitive computing… a potential recipe for a very nice mess…
It is therefore CRUCIAL that you introduce proper Strategic Data Management/Master Data Management principles as a matter of priority, or you WILL drown in data, especially with BIG DATA and cognitive computing approaching all of us at breakneck speed…
